Safe Agents with Guardrails.ai
Large Language Model (LLM) agents are powerful tools capable of responding to various user queries—whether trivial, complex, or potentially harmful. However, unguarded AI systems can inadvertently produce inappropriate, toxic, or misleading content. Guardrails become essential here to ensure that LLM outputs stay within acceptable boundaries, preserving both user trust and brand integrity.
Below is a visualization of how an agent without guards compares to one with guardrails in place:

Source: Guardrails.ai
In this example, we show how to build an LLM-powered agent that is guarded against unwanted or harmful outputs. We
use Guardrails.ai for toxicity filtering and DSPy for core language
model functionalities. We also added PII Masking with Presidio, ensuring sensitive data (like emails) is replaced
with <EMAIL_ADDRESS> before further processing:
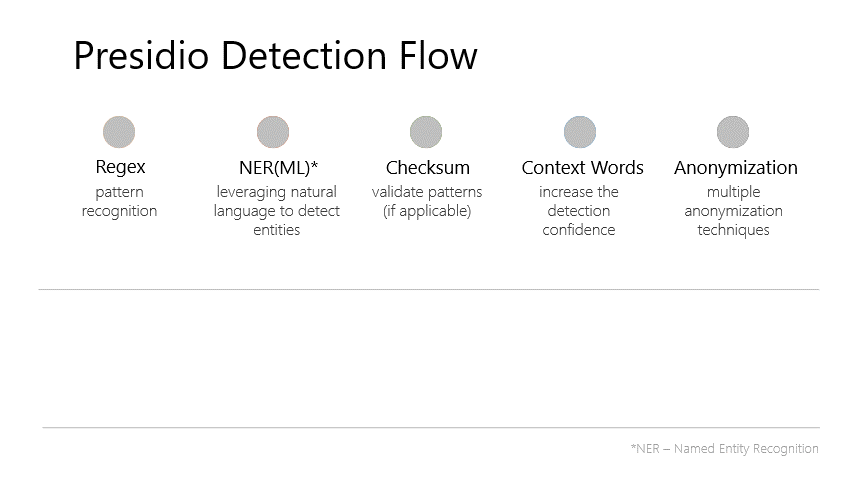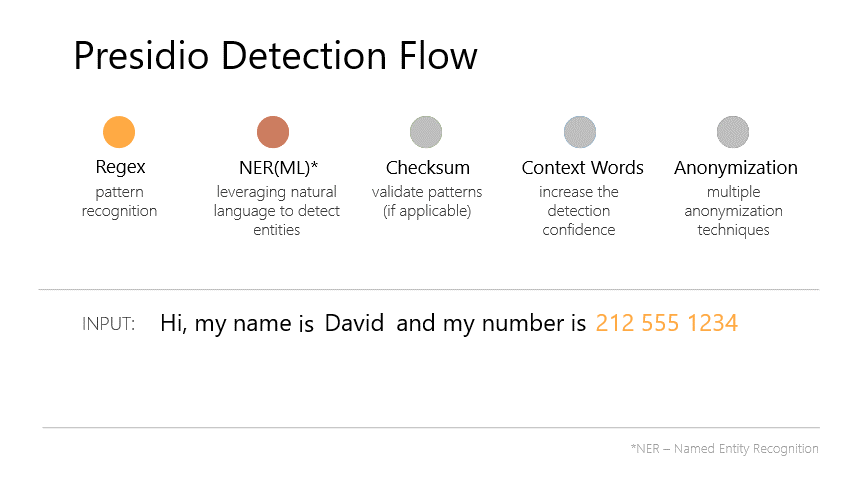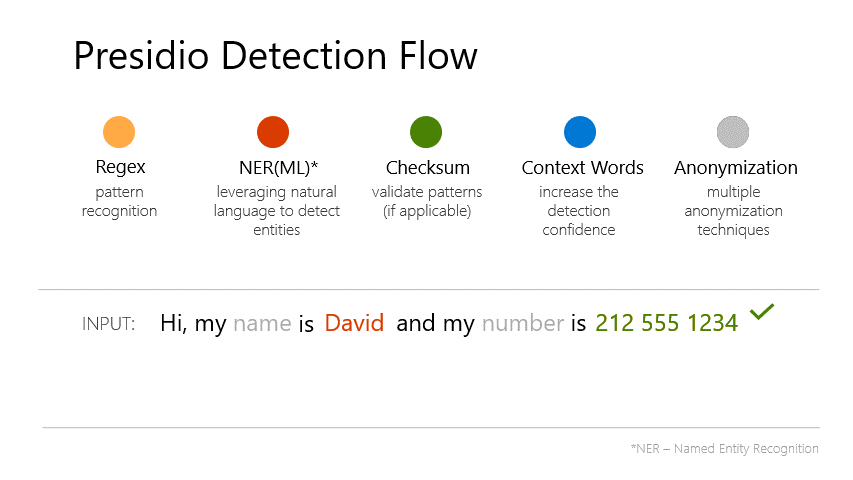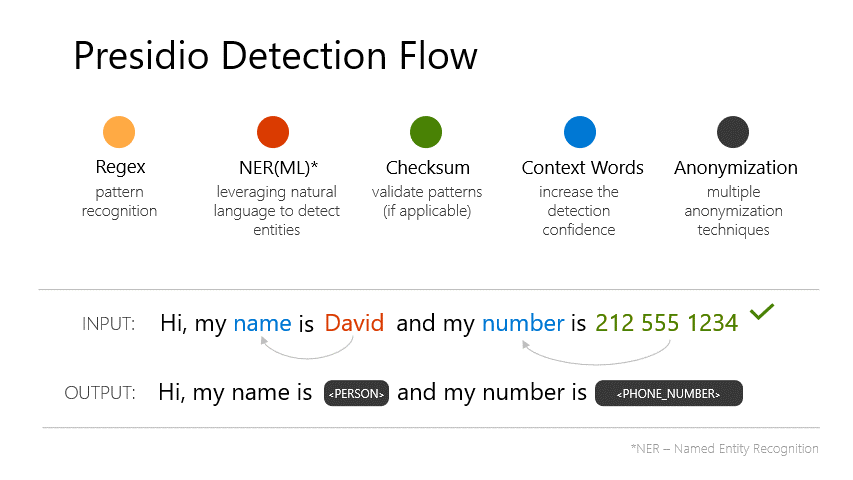
Source: Microsoft Presidio
The result is a multi-agentic system that can handle user queries responsibly while maintaining a high level of safety and reliability. Code for this example is available here.
Overview of the Approach
Input Guard: The answers_agent subscribes to new messages on the agents channel. Upon receiving a
"question",
we:
Check PII: If emails are found, they are masked with <EMAIL_ADDRESS> (via Presidio).
Check Toxicity: If the text is still deemed toxic, we publish an INPUT_GUARDRAIL error and stop processing.
Answer Generation: If the input is safe, the agent calls wiki_qa(question=question) to generate an answer.
This specialized module searches an offline Wikipedia corpus to provide relevant information.
Output Guard: We run the toxicity check again on the generated answer. If the answer is flagged, we publish an
OUTPUT_GUARDRAIL error, preventing any harmful content from reaching the user.
Publishing the Result: If both the question and answer pass guardrails, the safe, validated answer is published
back to the agents channel for consumption by other parts of the system.
Prerequisites
- Python 3.10+
- Docker and Docker Compose
- Valid OpenAI API key in your environment:
Setup Instructions
Clone the EggAI repository:
Move into the examples/litellm_agent folder:
Create and activate a virtual environment:
Install the required dependencies:
Configure Guardrails:
guardrails configure
guardrails hub install hub://guardrails/toxic_language
guardrails hub install hub://guardrails/detect_pii
Start Redpanda using Docker Compose:
Run the Example
Run Tests
Expected behaviour
Watch the console for the agent’s answer to the test questions:
- The first query involves a math-related, Wikipedia-augmented question.
- The second query (“Are you stupid??”) is caught by the toxicity filter, returning a safe fallback response.
- An example with an email address in the question will show masked output (
<EMAIL>).
Next Steps
- Additional Guards: Check out Guardrails.ai’s documentation to chain multiple guards for diverse content moderation needs.
- Scale Out: Integrate with more advanced DSPy pipelines or domain-specific systems (e.g., CRM, knowledge bases).
- CI/CD Testing: Use
pytestor similar to maintain performance and safety standards through version upgrades. - Contribute: Open an issue or submit a pull request on EggAI to enhance our guardrails example!
Enjoy creating safe, scalable, and versatile LLM-powered agents! For any issues, reach out via GitHub or the EggAI community.